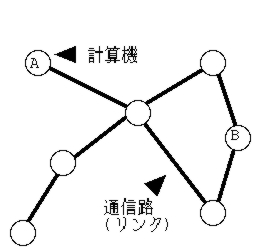
 |
| Fig.: example of a network |
Let a computer A want to communicate with other computer B. Here, all the computers can communicate directly only with the neighboring ones. If a computer wants to communicate with the non-neighboring one, it needs to use packet switching to exchange information. In this case, how the computer A can communicate with the computer B?
If these computers are neighboring with each other, the answer is clear. Otherwise, the computer A needs to ask one of the neighboring computers to deliver the message to B. This selected computer needs to ask another computer to deliver it, too. In this case, each computer should consider about not only which computer should it ask but also the following demand: the message should be sent as fast as possible or wasteful communication should be reduced.
If all the computers have the map about the network, each computer can easily determine the one it should ask. However, this map is not usually available for a computer when all the computers in the world are connected. This is because this map becomes too large to use for a computer. Furthermore, if the network topology varies from hour to hour, like the Internet, the computer cannot know the correctness of its map.
The distributed system is such a network consisting of computers and communication links like above figure. In general, it is impossible for a computer to know the whole topology in the system. This makes the design of the algorithm difficult even the following basic demand: the computer A wants to communicate with the computer B.
Moreover, failures of some computers or changes about the neighboring computers may happen at every moment. Therefore, it is required that the algorithm be fault-tolerance or flexible. We study the algorithm which has above property and imposes less wasteful communication .